

比人类专家快2倍,斯坦福联合英伟达发布TTT-Discover:用「测试时强化学习」攻克科学难题
比人类专家快2倍,斯坦福联合英伟达发布TTT-Discover:用「测试时强化学习」攻克科学难题在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?
来自主题: AI技术研报
10127 点击 2026-01-28 14:55
在技术如火如荼发展的当下,业界常常在思考一个问题:如何利用 AI 发现科学问题的新最优解?
过去两年,大模型的推理能力出现了一次明显的跃迁。在数学、逻辑、多步规划等复杂任务上,推理模型如 OpenAI 的 o 系列、DeepSeek-R1、QwQ-32B,开始稳定拉开与传统指令微调模型的差距。直观来看,它们似乎只是思考得更久了:更长的 Chain-of-Thought、更高的 test-time compute,成为最常被引用的解释。
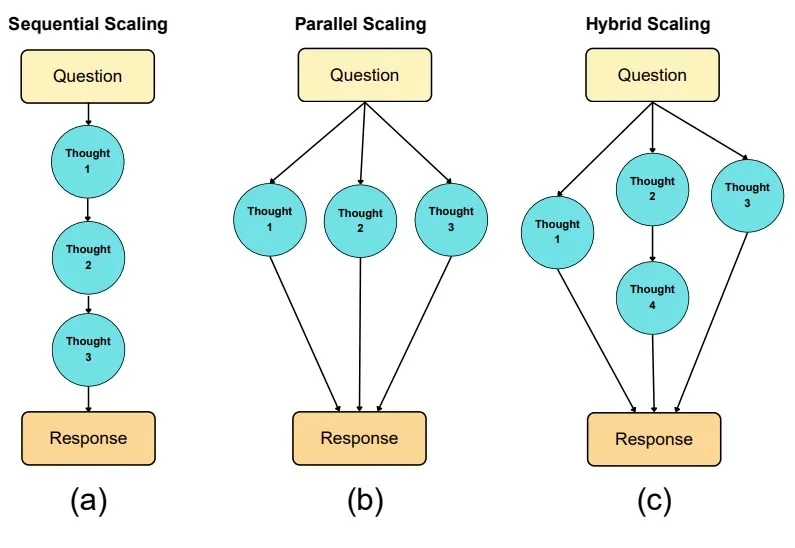
如果说大模型的预训练(Pre-training)是一场拼算力、拼数据的「军备竞赛」,那么测试时扩展(Test-time scaling, TTS)更像是一场在推理阶段进行的「即时战略游戏」。

大模型推理的爆发,实际源于 scaling 范式的转变:从 train-time scaling 到 test-time scaling(TTS),即将更多的算力消耗部署在 inference 阶段。典型的实现是以 DeepSeek r1 为代表的 long CoT 方法:通过增加思维链的长度来获得答案精度的提升。那么 long CoT 是 TTS 的唯一实现吗?
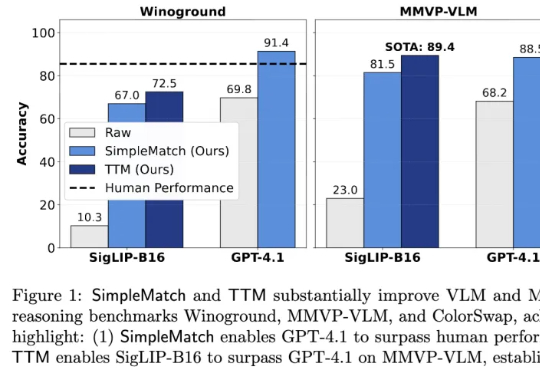
加州大学河滨分校团队发现,AI组合推理表现不佳部分源于评测指标过于苛刻。他们提出新指标GroupMatch和Test-Time Matching算法,挖掘模型潜力,使GPT-4.1在Winoground测试中首次超越人类,0.2B参数的SigLIP-B16在MMVP-VLM基准测试上超越GPT-4.1并刷新最优结果。这表明模型的组合推理能力早已存在,只需合适方法在测试阶段解锁。
在大语言模型(LLM)席卷各类复杂任务的今天,“测试时扩展”(Test-Time Scaling,TTS)已成为提升模型推理能力的核心思路 —— 简单来说,就是在模型 “答题” 时分配更多的计算资源来让它表现更好。严格来说,Test-Time Scaling 分成两类:
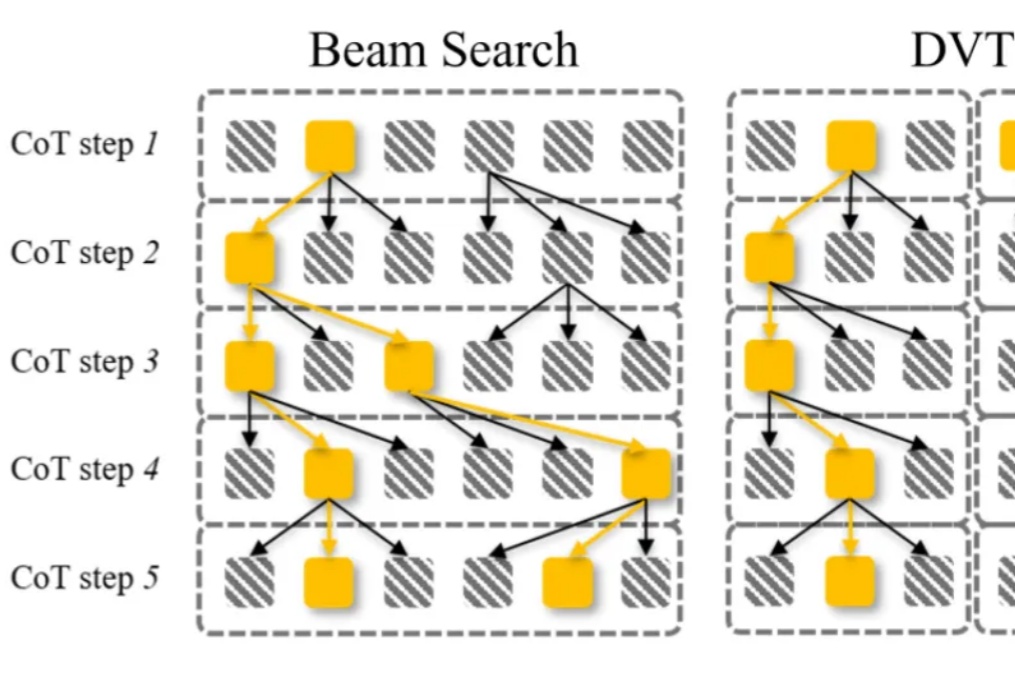
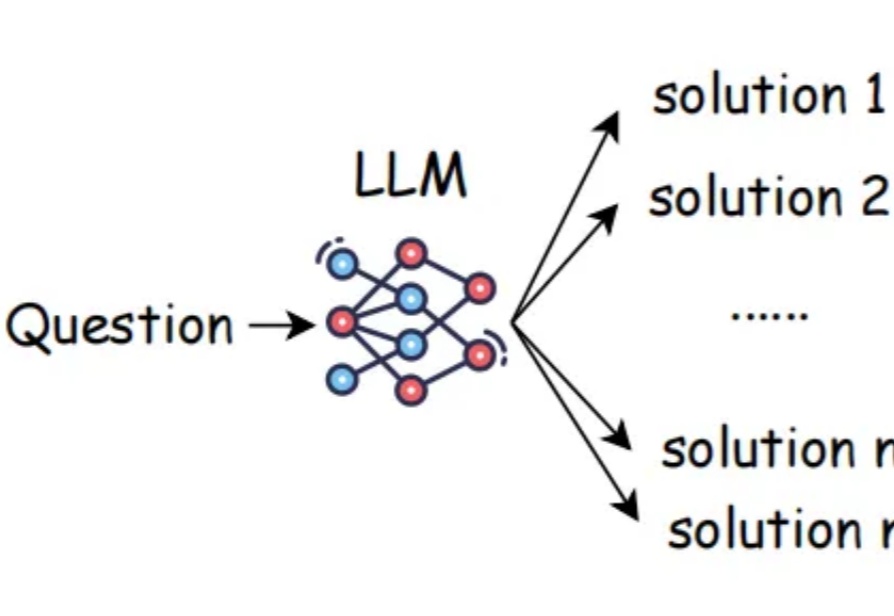
大语言模型通过 CoT 已具备强大的数学推理能力,而 Beam Search、DVTS 等测试时扩展(Test-Time Scaling, TTS)方法可通过分配额外计算资源进一步提升准确性。然而,现有方法存在两大关键缺陷:路径同质化(推理路径趋同)和中间结果利用不足(大量高质量推理分支被丢弃)。
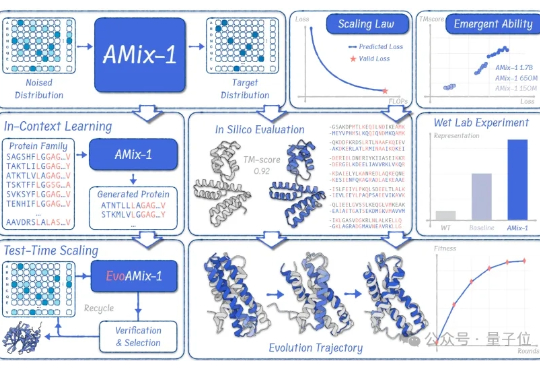
蛋白质模型的GPT时刻来了! 清华大学智能产业研究院(AIR)周浩副教授课题组联合上海人工智能实验室发布了AMix-1: 首次以Scaling Law、Emergent Ability、In-Context Learning和Test-time Scaling的系统化方法论来构建蛋白质基座模型。

测试时扩展(Test-Time Scaling)极大提升了大语言模型的性能,涌现出了如 OpenAI o 系列模型和 DeepSeek R1 等众多爆款。那么,什么是视觉领域的 test-time scaling?又该如何定义?

《Why We Think》。 这就是北大校友、前OpenAI华人VP翁荔所发布的最新万字长文—— 围绕“测试时计算”(Test-time Compute)和“思维链”(Chain-of-Thought,CoT),讨论了如何通过这些技术显著提升模型性能。